- #Umelá inteligencia
- 3 min.
- 18.7.2024
Apple, NVIDIA a ďalší bez povolenia využili YouTube videá na tréning svojich AI


YouTube má vo svojich podmienkach jasne stanovené, že videá nahrané na jej platforme nesmú byť obsiahnuté vo veľkých dátových balíkoch na tréning umelej inteligencie.
Aj napriek tomu sa viac ako 173-tisíc videí objavilo v dátovom balíku, na ktorej svoje AI modely trénovali spoločnosti ako Apple, Anthropic, NVIDIA, Salesforce a ďalšie.
Dátový balík pozostáva z titulkov videí viac ako 48 000 známych YouTube kanálov, medzi nimi napríklad aj MrBeast, MKBHD, ABC News, BBC, The New York Times a mnohých ďalších známych osobností a médií. Jedná sa teda výhradne o textové dáta, bez záznamov obrazu alebo zvuku.
Spoločnosti Anthropic a Salesforce potvrdili využitie verejne dostupného dátového balíka s názvom Pile, ktorého súčasťou sú aj spomínané titulky YouTube videí, no aj napriek zjavnému porušeniu podmienok tejto videoplatformy odmietajú akékoľvek previnenie. NVIDIA sa k situácii odmietla vyjadriť, Apple, Databricks a Bloomberg na žiadosť o komentár neodpovedali.
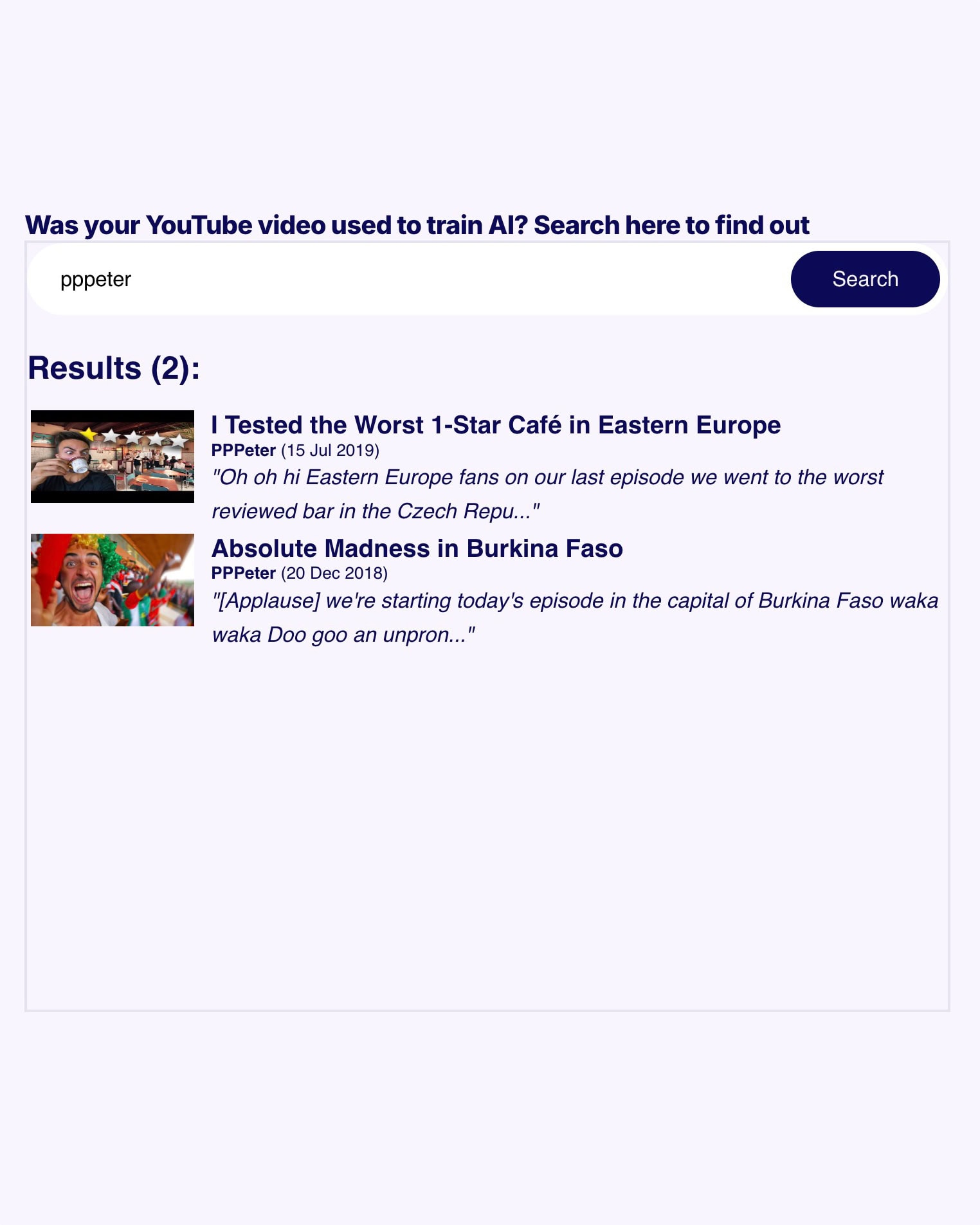
Vo veci sa na tieto spoločnosti obrátil priamo neziskový portál Proof News, ktorý tento prešľap odhalil a tiež získal prístup k problematickým tréningovým dátam. Portál vytvoril špecializovaný vyhľadávač, prostredníctvom ktorého môžete zistiť, či sa konkrétne video alebo kanál vyskytuje v použitom dátovom balíku. Nájsť v ňom môžete prevažne kanály publikujúce obsah v anglickom jazyku, medzi nimi napríklad aj dve videá slovenského youtubera známeho ako PPPeter.
Dátový balík The Pile, ktorý všetky menované spoločnosti využili, je 825 GB open-source kolekciou neziskovej organizácie EleutherAI, ktorého súčasťou sú aj ďalšie typy dát vrátane vedeckých článkov článkov a textov z Wikipedie.
Netransparentnosť spoločností v zdrojovaní dát, ktoré využili na tréning svojich AI modelov, nie je ničím novým pod slnkom. Týmto obvineniam už opakovane čelila aj spoločnosť OpenAI, ktorá okrem četbota ChatGPT vyvíja aj nástroj na generovanie AI videí zvaný Sora.
V rozhovore pre The Wall Street Journal technologická riaditeľka Mira Murati odmietla konkretizovať, aké dáta spoločnosť na tréning modelu Sora využila, no jednať sa malo o „verejne dostupné alebo licencované dáta“. V otázke, či sa medzi nimi nachádzajú aj YouTube videá, Murati uviedla, „že si tým nie je istá“.